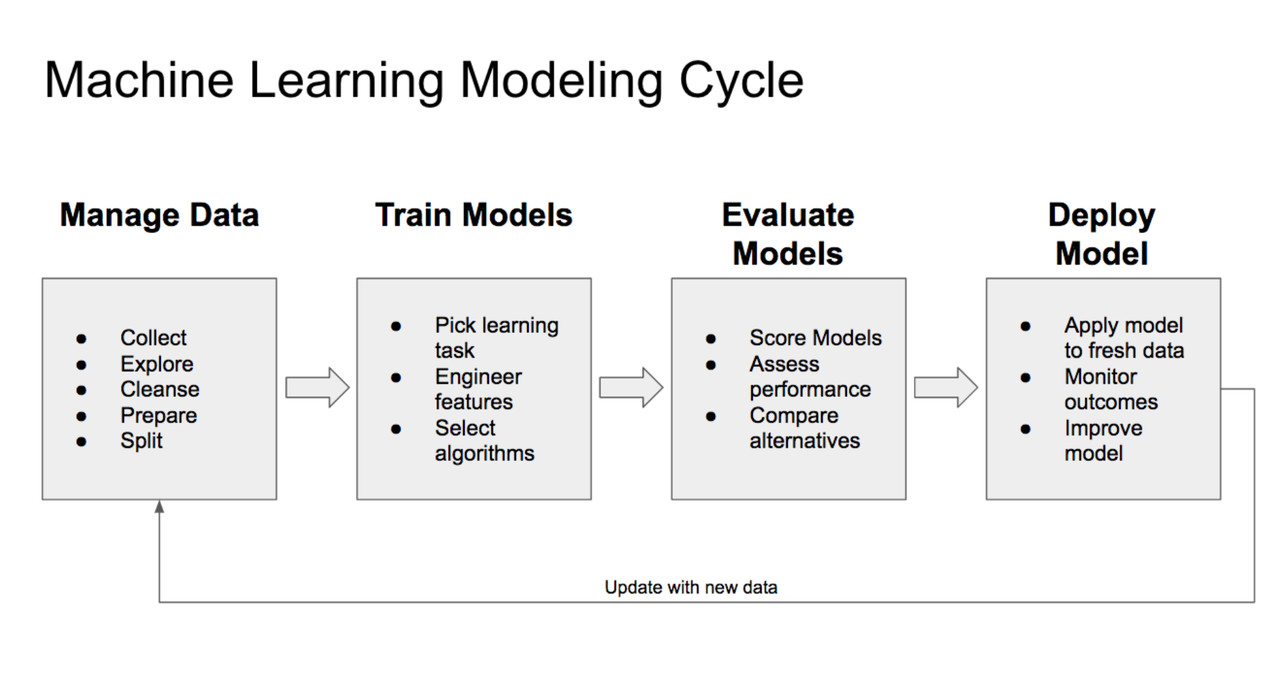
4 Stages of the Machine Learning (ML) Modeling Cycle
What does a project involving the development of a machine learning model look like? What are the stages and activities involved? In this article, I give a layman's view of the 4 stages of a typical machine learning modeling cycle, and apply it to a small use case in order to make it real. If you are interested in starting a project involving machine learning, read on.
First off: What is Machine Learning?
One of the better machine learning definitions that I have come across is that machine learning is "the field of study that gives computers the ability to learn without being explicitly programmed."
Another good definition that is slightly more technical is that machine learning is "the use of algorithms to extract information from raw data and represent it in some type of model. We use this model to infer things about other data we have not yet modeled."
In other words, you teach the computer: "If it looks like a cat, is shaped like a cat, and has the features of a cat, then chances are it probably is a cat."
So how do we teach the machine to learn?
A machine learning project typically follows a cycle similar to the diagram above. You start with a data management stage where you collect a set of training data for use. Once you have collected the training data, you need to explore the data to get a better understanding of its structure and meaning. The data will typically need to be cleansed in order for it to be useful, this may involve formatting and vectorization (a process meant to turn data into the mathematical constructs that ML models understand). Once cleansed you will need to further prepare the data for loading into your programming environment. Finally, you have to split your data into training and validation subsets.
After the data has been properly prepared, we are ready to train ML models. In the Train Model stage, we decide on the overall approach by picking a learning task (i.e. prediction, clustering, etc.). We typically need to study the available featuers in the training data set and engineer some new features if necessary (although deep learning neural networks have automatic feature generation). Finally, we select appropriate algorithms to train the models.
In the third stage, we evaluate the output of the models using different approaches and algorithms. We score the models using suitable metrics such as F1 score, precision, recall and accuracy rate. We assess the time efficiency of the various models, and we develop and compare new alternatives. We further tweak the hyperparameters of the models until we are satisfied with a "good" model, and then we can proceed to the final stage.
In the final stage, we apply the model to fresh data and monitor outcomes. Here we enjoy the fruits of our labor and make predictions or inferences on data that we have never explored before. We learn from these observations and if necessary, we improve the model until the cycle starts again.
To illustrate this cycle better, I will apply this to a mini use case that I ran on my home computer using off-the-shelf software.
My “use case”: Sorting through financial transactions
In this use case, the problem is to classify financial transactions from monthly financial statements into types of transactions(e.g. ‘Property Tax’, ‘Eating Out’, ‘Clothing’). The goal is to have the machine look at each transaction and automatically classify it based on the description, amount, and date of each transaction. There are free apps available to do this kind of task, personally I need a higher degree of customization and control than is offered by these free apps. So I decided to build my own.
In the past I have used Excel models and vlookup?tables to automate the sorting task as much as possible. The challenge is the transaction descriptions keep changing and new vendors keep propping up, so a formula/rule-based method can only take you so far – in fact, the highest accuracy rate I ever got with the Excel system is around 55%. I have to manually update the rest. Also, over time the block of Excel code became very unwieldy. Not fun!
The tool: Dataiku’s Data Science Studio
I came across?Dataiku’s DSS platform?recently and liked its promise of easy?prototyping and deployment in a collaborative fashion. DSS offers a free edition that includes many features for data connection, data transformation, data visualization, data mining, and most interestingly, machine learning. So I gave it a try.
Stage 1: Data Management
I started with the data management stage by going back to my archived banking statements. In all, there were about six thousand transactions in the last 4-5 years. Over the years, I already manually labeled each transaction and assigned each to a unique account (or category). This dataset will be used the “train” the model later on, but before I could use it I needed to do some data exploration, cleansing, and preparation.
The initial dataset looked like any ordinary table with columns for ‘cash date’, ‘channel’, ‘description’ etc. Unlike good-old Excel, DSS does not need to load all the rows of data in order to manipulate the data set. This allows you to manipulate the data efficiently and deal with large datasets that may load outside of your computer’s memory.
The data set came in with various issues such as invalid data types, missing/empty columns or rows, and mislabelled data. This is all very typical. To cleanse the data, I removed a number of columns, parsed the dates into a better format, replaced some values for certain entries, and got rid of some invalid data. DSS includes excellent tools to create scripts (or “recipes”) to cleanse my data set.
The advantage of this approach is that I can save my steps and reapply the same steps in the future. For example, if I want to refresh my training dataset later, I can easily retrace my steps using the script. I can also easily share my scripts with other people, so if I were working as part of a team, I would be able to point my teammates to my script and they would be able to figure out exactly what steps I took to cleanse the data.
Stage 2: Create and Train the Models
Now comes the fun part. In this case, I have a set of prepared data (the 4-5 years of financial transactions) and I wanted to predict which category based on the description of the transaction. This type of use-case lends itself very well to a supervised training algorithm, so I selected “prediction” when DSS presented me the choice.
Once I have gone down the path of prediction, I am given further choices to define the parameters of my model. I selected the variable that I wanted to predict (“ACCOUNT”) and then sifted through a menu of model templates ranging from “Balanced” to “Performance”.
Each template gives you several specific algorithms, such as linear regression, gradient tree boosting and neural networks. I'll write about the meaning of these different algorithms in the future. For now, just be aware that they are available for use and will generate different results depending on your use case. Your job is to pick the most appropriate algorithm in order to get the best predictive results.
A really nice feature of DSS is integration with other open source machine learning platforms such as Python SciKit, XGBoost, Spark MLLib, H2O Sparkling Water, and Vertica Advanced Analytics. The free edition integrates in-memory training using popular Python libraries such as SciKit and XGboost.
I was able to fine-tune the model parameters including the optimization goal (F1 score, accuracy, precision, recall, area-under-curve, log loss). There are additional options to set up the train job including validation/testing policy, sampling, splitting and hyperparameters.
Feature Engineering
DSS provides some flexibility over which features to include, how to handle each included feature, and live on-screen visualizations of each feature set.
I am able to further tweak the parameters used to train each unique type of algorithm. For instance, under the Gradient Boosted Tree algorithm, I can define the number of boosting stages, the feature sampling strategy, learning rate, loss and the maximum depth of the tree. The artificial neural network algorithm has its own set of parameters to tweak.
Once all the fine-tuning is done all that is left to do is to train the models. DSS does a good job keeping you up to date on the progress of the training. On my Apple Mac Mini with 2.3GHz i7 processor, 16Gb of memory, and a small set of data, my models trained very quickly (1-2 minutes on average). In production environments, you would expect the time to be higher depending on the computing resources you have at hand.
Stage 3: Evaluating the models
When the models have been successfully trained, DSS summarizes the key metrics used to measure model performance in a nice table. My task now is to assess the performance of each model and select the best one.
I started with a list of about 7-8 models and quickly whittled this down to the top two which were Gradient Tree Boosting and Artificial Neural Network. The other ones either didn’t train well at all, or the performance metrics were significantly poorer than the top two.
From this point on it was a matter of tweaking the parameters of the top two models and iterating the process in search for ever better metrics. This is typical and similar to what you would do in a production environment where the search for better models becomes a significant endeavor in itself.
After a bit of trial and error, I ended up selecting a model based on the Gradient Tree Boosting algorithm, which offered a pretty good accuracy rate of around 80% and ROC AUC of almost 95%. I decided to take this model for a spin with real up-to-date data to see how it fares.
Stage 4: Deploying the Gradient Tree Boosted Model
I was really excited to apply my new model to my latest set of bank statements. I downloaded the monthly statements (by the way this is a great task to automate using RPA, or Robotic Process Automation, but lets save that for another day). I then used the new model to predict the account based on the descriptions of the transactions, just as I wanted to to do in my original goal.
Within seconds, my model spit out classifications for each transaction. And the classifications looked really good! As I quickly glanced through the results, I was impressed by the fact that the machine did a fantastic job predicting the account based on the description of the transaction.
So, in the end, how did the machine perform compared to the human (me)? Well you can recall from earlier that the Excel vLookup method yielded an accuracy rate of about 55%. My new machine learning model yielded a test accuracy of 85%. A 30% improvement in prediction accuracy! Not bad for a quick afternoon’s work.
Sharing the model
An important step in any machine learning project is to share your data set, model and outcomes with your team members. Many software solutions have built-in dashboards for sharing information and status of the modeling process. Beyond the dashboards, one of the most useful features is the ability to output your entire workflow as an iPython Notebook. iPython Notebooks are very popular amongst data scientists as they provide an interactive environment, in which you can combine code execution, rich text, mathematics, plots and rich media. You should be able to read my iPython notebook and follow my work flow easily, and even make interactive changes to the code base to share back with me.
By inspecting my iPython notebook, you can see that my workflow has utilized several popular Python libraries including numpy, pandas and sklearn. If you are well versed in Python you can dive right in to modify the code base or even create custom Python recipes.
A quick re-cap
We’ve walked through a pretty standard machine learning development process using a modern data science tool called Dataiku DSS. We started off by defining our goal and determining whether there is reason to believe that a machine can out-perform a human. Once we said yes to those questions, we had fun collecting and preparing our data. When the data was ready, we built and trained the models using various algorithms. The process quickly turned into an iterative cycle where I tweaked the parameters of the algorithms in an effort to optimize my model. In the end I satisfied myself with a gradient tree boosted machine learning model, and I applied a fresh set of data to see how well the model behaved in the real world. The results were good and I was a happy man.
Key Take Aways
Let me leave you with a few takeaways:
If you liked this blog, please share this with your friends on social media, it helps tremendously!
#MachineLearning #AI #ArtificialIntelligence
Seeking Investment for Educational Projects, Selling IOT Services, Fleet Management, Business Collaboration Services, Corporate Internet, SIP Trunking, ERP, CRM, POS, Hospital Management and other Business Solutions
1 年Maurice Chang Thank you for sharing valuable information.
Undergraduate Student at Informatics Institute of Technology
1 年thankx
Business Intelligence Analyst | Microsoft Power BI | Rstudio | Microsoft PowerPoint | Excel | Helping individuals and businesses communicate more effectively with data
1 年Thanks a bunch for sharing this, this was a good read and great learning opportunity for me.
Electrical Design| Power System Engineer|MATLAB & Simulink| Power Distribution| ETAP| PowerWorld| Python| AI/ML
1 年Well illustrated,??
Data Lover | Lifelong Learner
1 年Tnx ??